环境架构说明:
Windows 2008 Server R2 Enterprise
Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.1 (X64)
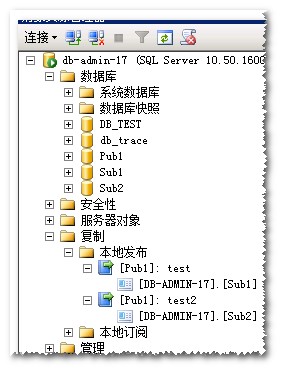
一个发布库Pub1,两个订阅库Sub1、Sub2
发布库Pub1中有一张表T_test,需要发布订阅到Sub1和Sub2,由于某些原因,我创建了两个发布[Pub1]:test和[Pub1]:test2分别向Sub1和Sub2进行复制。
现在我因为业务需求,需要对T_test表进行大批量更新操作,为了避免出现延迟,我决定采用在事务复制中发布存储过程执行
我为发布[Pub1]:test添加这个存储过程项目,并更改属性为存储过程的执行,注意这个时候我还没有为发布[Pub1]:test2添加这个存储过程。
于是我执行该存储过程,发现Sub1已经完成T_Test的数据更改,而当我去查看Sub2时,却发现没有更改!
我是这样认为的:第一个发布中包含了T_test表的复制,也包含了一个针对该表更新的存储过程的执行,如果我执行存储过程,那么应该把存储过程的执行复制到订阅端,这个没有问题。
第二个发布包中值包含了T_test表的复制,没有包含该存储过程的发布,在我没有为第一个发布添加存储过程执行前,是可以正常复制更改至Sub2的,那么即使我现在
为第一个发布包增加了存储过程的执行,那么第二个发布包是否也应该用之前的方式,生成逐条更改T_test表的事务并应用于订阅端呢?
在示例中是Pub1分别通过[Pub1]:test,[Pub1]:test2向Sub1,Sub2中进行复制。
以下是建表脚本
use pub1
create table t_test(id int identity(1,1) primary key,col varchar(10))
insert into t_test select 'a'
go 1000
insert into t_test select 'b'
go 1000
select * from t_test
--创建批量执行存储过程
alter PROC P_TEST
AS
UPDATE t_test SET col='AB' WHERE id<=1000
然后在第一个发布里面添加存储过程,并设置属性为执行存储过程
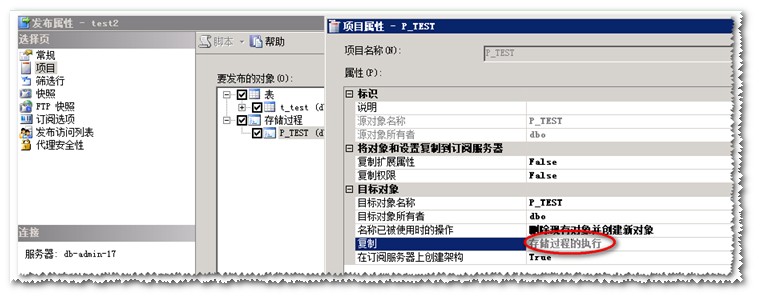
生成快照后,我们在发布库执行存储过程:EXEC P_TEST
然后我们悲催的发现发布test下面的Sub1下面的表已更新,发布test2中Sub2下面的表却不更新